
Vue源码学习笔记之compile
在底层的实现上,Vue 将模板编译成虚拟 DOM 渲染函数。
那么Vue在何时进行模版编译的呢?答案是Vue.prototype.$mount被调用的时候。我们知道,当您传入”el”选项时,Vue.prototype.$mount会在vm实例化时自动调用,否则,需要通过vm.$mount手动调用。
0. $mount
用一张图简要描述$mount的调用过程:
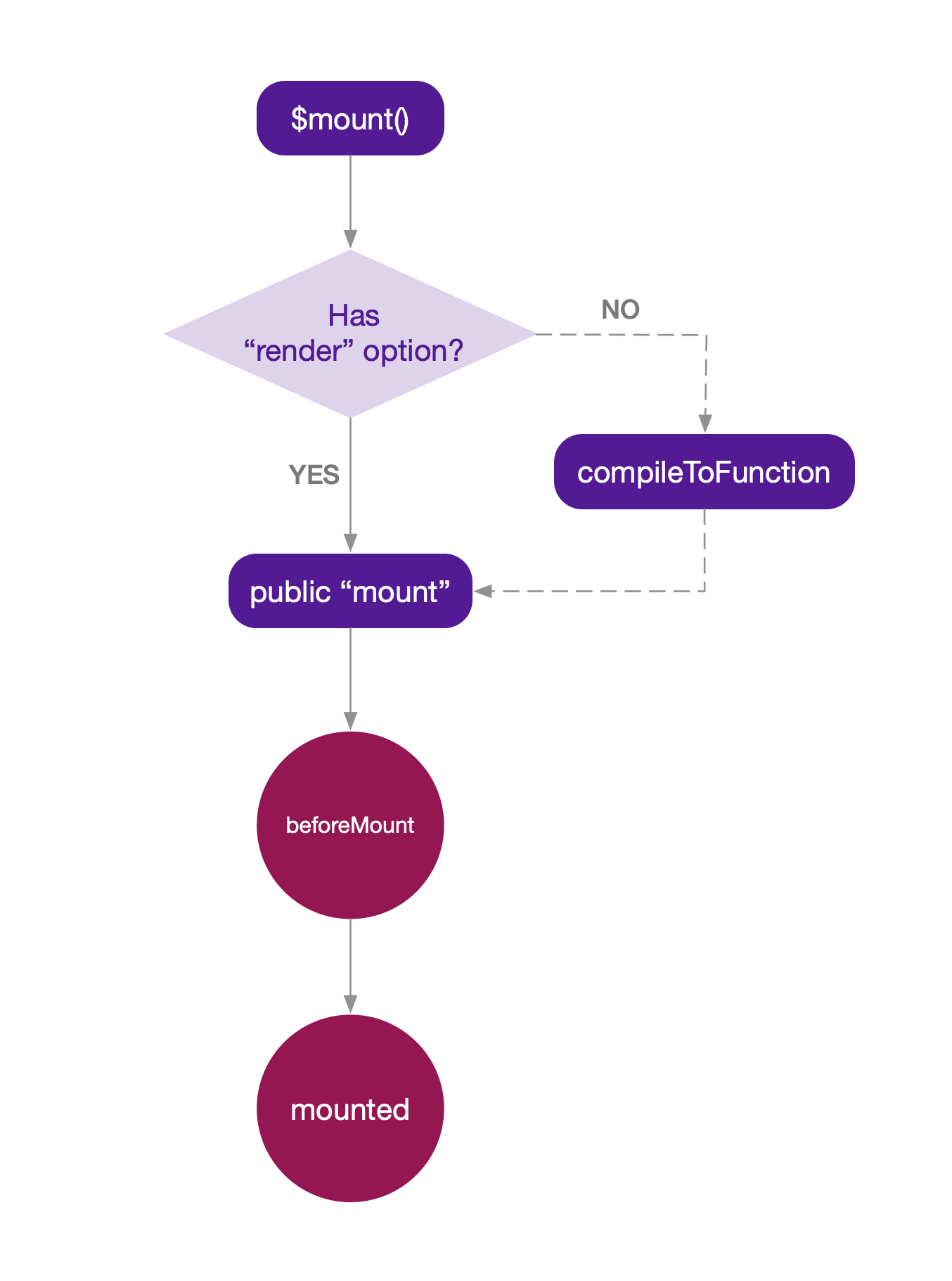
源码对$mount方法进行了两次定义,一次是在’runtime/index.js’(称作:public mount)中,另一次是在’entry-runtime-with-compiler.js’(称作:compile mount)中,实际上compile mount是对public mount的扩展,我们来看源码:
const mount = Vue.prototype.$mount
Vue.prototype.$mount = function (
el?: string | Element,
hydrating?: boolean
): Component {
el = el && query(el)
// ...
const options = this.$options
// resolve template/el and convert to render function
if (!options.render) {
let template = options.template
if (template) {
if (typeof template === 'string') {
if (template.charAt(0) === '#') {
template = idToTemplate(template)
}
} else if (template.nodeType) {
template = template.innerHTML
} else {
return this
}
} else if (el) {
template = getOuterHTML(el)
}
if (template) {
// ...
const { render, staticRenderFns } = compileToFunctions(template, {
shouldDecodeNewlines,
delimiters: options.delimiters,
comments: options.comments
}, this)
options.render = render
options.staticRenderFns = staticRenderFns
// ...
}
}
return mount.call(this, el, hydrating)
}
如上图所示,compile mount首先判断您是否提供了”render”选项,如果有就直接执行public mount;如果没有就检查您是否提供了”template”选项,如果提供了就把template转换成htmlString,如果没有再检查您是否提供”el”选项,提供了就将el转换成htmlString赋值给template。
template转换完成后执行compileToFunctions,compileToFunctions返回了render函数和staticRenderFns函数。
最后执行public mount。public mount主要执行mount相关的生命周期函数,这里不详述。我们重点看看compile过程。
1. compile
compile的全部过程通过调用compileToFunctions来完成,源码用了大量的闭包最终暴露出compileToFunctions,我在看的时候被绕得不轻,在此将它梳理成一张图来说:
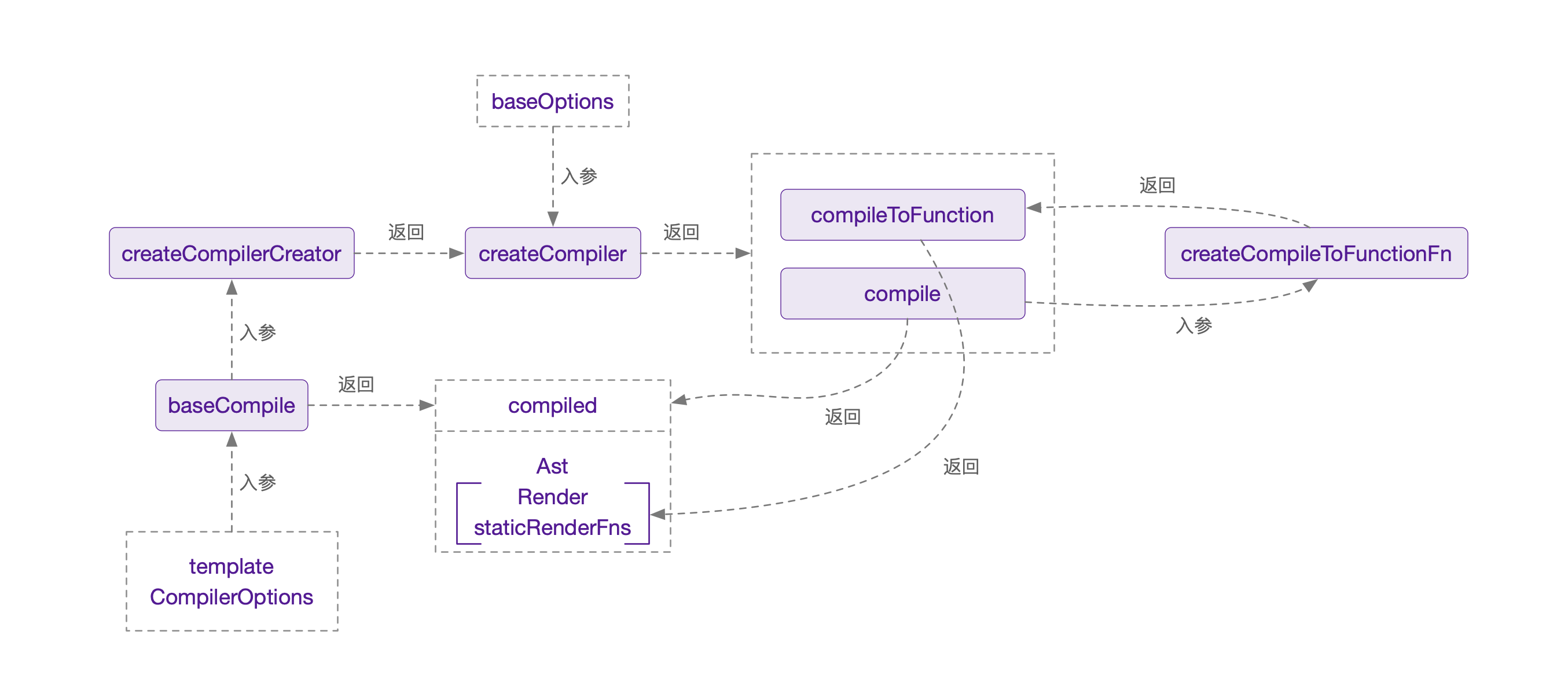
这里面实际上最关键的是baseCompile函数,它负责编译template。
function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
const ast = parse(template.trim(), options)
optimize(ast, options)
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
}
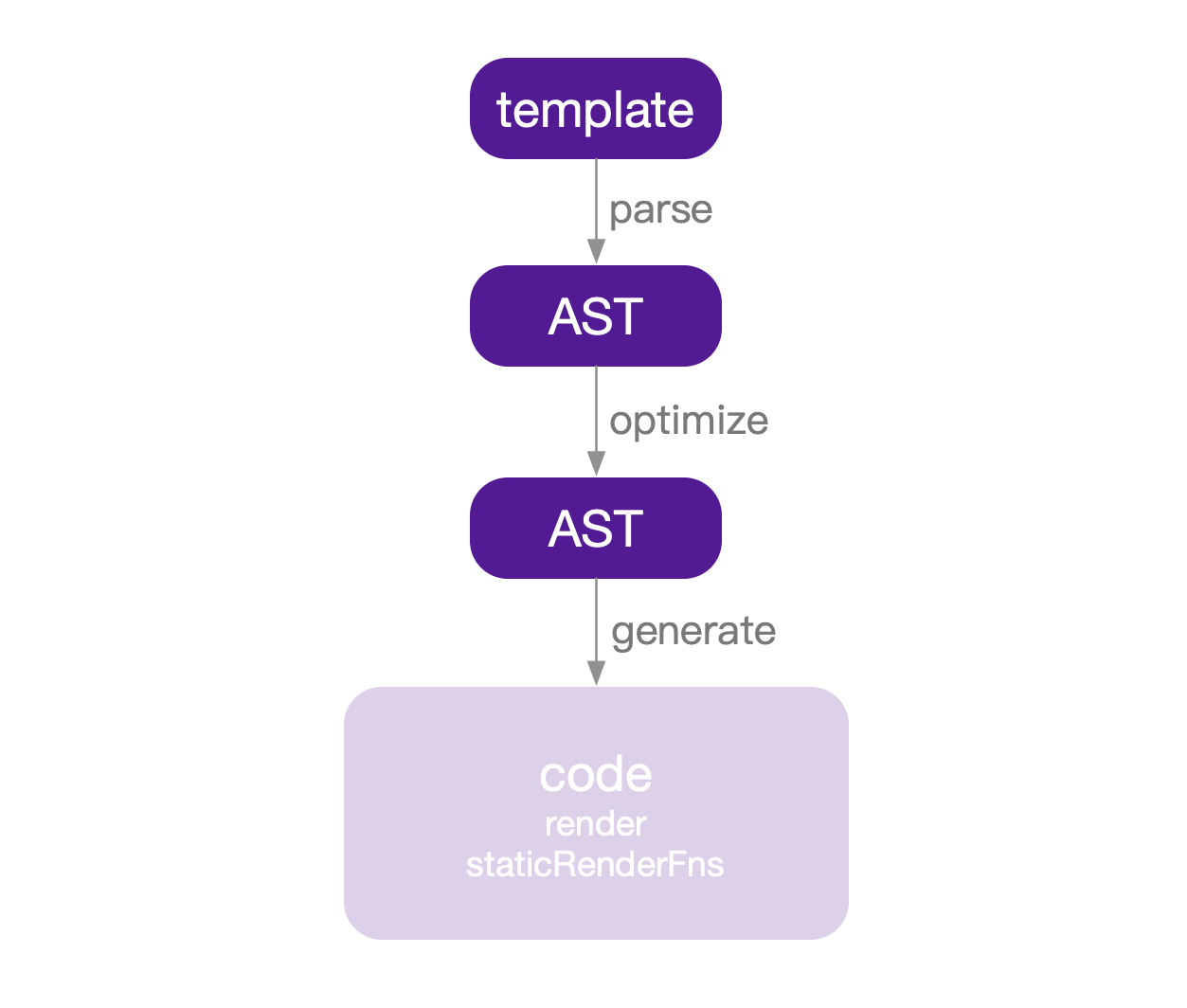
整个编译过程如下:
1.0. 编译器
这里先介绍一下编译器。大多数现代编译器的编译过程可以分为三个阶段:解析、转译、代码生成。
-
Parse(解析):将原始的物理行代码转换为更抽象的结构。解析又可细分为两个阶段:
1.词法分析。通过词法分析器将源代码分成tokens数组,tokens由描述独立语法的一个个微小对象组成,例如标签,运算符,标点符号等等。
2.语法分析。将tokens重新格式化为描述每个部分及其它语法之间的关系的结构。即抽象语法树(AST)。
- Transformation(转译):对抽象语法树进行进一步处理,甚至转换为另一种语言。
- Code generate(代码生成):将AST转换为可执行代码(机器码)。
AST, Abstract Syntax Tree, 是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
1.1. Vue的模版编译
Vue把第二部替换成了优化,各个阶段分别做了以下的事情:
- parse:将htmlString转换成抽象语法树(Abstract Syntax Tree)。
- optimize:对抽象语法树中的静态子树进行标记,以便在重新渲染或patching时跳过它们节省开销。
- generate:由优化过的抽象语法树生成render函数字符串。
下面结合源码理解:
1.1.0. parse
/**
* Convert HTML string to AST.
*/
export function parse (
template: string,
options: CompilerOptions
): ASTElement | void {
warn = options.warn || baseWarn
platformIsPreTag = options.isPreTag || no
platformMustUseProp = options.mustUseProp || no
platformGetTagNamespace = options.getTagNamespace || no
transforms = pluckModuleFunction(options.modules, 'transformNode')
preTransforms = pluckModuleFunction(options.modules, 'preTransformNode')
postTransforms = pluckModuleFunction(options.modules, 'postTransformNode')
delimiters = options.delimiters
const stack = []
const preserveWhitespace = options.preserveWhitespace !== false
let root
let currentParent
let inVPre = false
let inPre = false
let warned = false
function warnOnce (msg) {
if (!warned) {
warned = true
warn(msg)
}
}
function endPre (element) {
// check pre state
if (element.pre) {
inVPre = false
}
if (platformIsPreTag(element.tag)) {
inPre = false
}
}
parseHTML(template, {
warn,
expectHTML: options.expectHTML,
isUnaryTag: options.isUnaryTag,
canBeLeftOpenTag: options.canBeLeftOpenTag,
shouldDecodeNewlines: options.shouldDecodeNewlines,
shouldKeepComment: options.comments,
start (tag, attrs, unary) {
// check namespace.
// inherit parent ns if there is one
const ns = (currentParent && currentParent.ns) || platformGetTagNamespace(tag)
// handle IE svg bug
/* istanbul ignore if */
if (isIE && ns === 'svg') {
attrs = guardIESVGBug(attrs)
}
let element: ASTElement = createASTElement(tag, attrs, currentParent)
if (ns) {
element.ns = ns
}
if (isForbiddenTag(element) && !isServerRendering()) {
element.forbidden = true
process.env.NODE_ENV !== 'production' && warn(
'Templates should only be responsible for mapping the state to the ' +
'UI. Avoid placing tags with side-effects in your templates, such as ' +
`<${tag}>` + ', as they will not be parsed.'
)
}
// apply pre-transforms
for (let i = 0; i < preTransforms.length; i++) {
element = preTransforms[i](element, options) || element
}
if (!inVPre) {
processPre(element)
if (element.pre) {
inVPre = true
}
}
if (platformIsPreTag(element.tag)) {
inPre = true
}
if (inVPre) {
processRawAttrs(element)
} else if (!element.processed) {
// structural directives
processFor(element)
processIf(element)
processOnce(element)
// element-scope stuff
processElement(element, options)
}
function checkRootConstraints (el) {
if (process.env.NODE_ENV !== 'production') {
if (el.tag === 'slot' || el.tag === 'template') {
warnOnce(
`Cannot use <${el.tag}> as component root element because it may ` +
'contain multiple nodes.'
)
}
if (el.attrsMap.hasOwnProperty('v-for')) {
warnOnce(
'Cannot use v-for on stateful component root element because ' +
'it renders multiple elements.'
)
}
}
}
// tree management
if (!root) {
root = element
checkRootConstraints(root)
} else if (!stack.length) {
// allow root elements with v-if, v-else-if and v-else
if (root.if && (element.elseif || element.else)) {
checkRootConstraints(element)
addIfCondition(root, {
exp: element.elseif,
block: element
})
} else if (process.env.NODE_ENV !== 'production') {
warnOnce(
`Component template should contain exactly one root element. ` +
`If you are using v-if on multiple elements, ` +
`use v-else-if to chain them instead.`
)
}
}
if (currentParent && !element.forbidden) {
if (element.elseif || element.else) {
processIfConditions(element, currentParent)
} else if (element.slotScope) { // scoped slot
currentParent.plain = false
const name = element.slotTarget || '"default"'
;(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element
} else {
currentParent.children.push(element)
element.parent = currentParent
}
}
if (!unary) {
currentParent = element
stack.push(element)
} else {
endPre(element)
}
// apply post-transforms
for (let i = 0; i < postTransforms.length; i++) {
postTransforms[i](element, options)
}
},
end () {
// remove trailing whitespace
const element = stack[stack.length - 1]
const lastNode = element.children[element.children.length - 1]
if (lastNode && lastNode.type === 3 && lastNode.text === ' ' && !inPre) {
element.children.pop()
}
// pop stack
stack.length -= 1
currentParent = stack[stack.length - 1]
endPre(element)
},
chars (text: string) {
if (!currentParent) {
if (process.env.NODE_ENV !== 'production') {
if (text === template) {
warnOnce(
'Component template requires a root element, rather than just text.'
)
} else if ((text = text.trim())) {
warnOnce(
`text "${text}" outside root element will be ignored.`
)
}
}
return
}
// IE textarea placeholder bug
/* istanbul ignore if */
if (isIE &&
currentParent.tag === 'textarea' &&
currentParent.attrsMap.placeholder === text
) {
return
}
const children = currentParent.children
text = inPre || text.trim()
? isTextTag(currentParent) ? text : decodeHTMLCached(text)
// only preserve whitespace if its not right after a starting tag
: preserveWhitespace && children.length ? ' ' : ''
if (text) {
let expression
if (!inVPre && text !== ' ' && (expression = parseText(text, delimiters))) {
children.push({
type: 2,
expression,
text
})
} else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') {
children.push({
type: 3,
text
})
}
}
},
comment (text: string) {
currentParent.children.push({
type: 3,
text,
isComment: true
})
}
})
return root
}
parse执行了parseHTML方法,这是将htmlString解析成AST的关键函数,展开parseHTML。
function parseHTML (html, options) {
const stack = []
const expectHTML = options.expectHTML
const isUnaryTag = options.isUnaryTag || no
const canBeLeftOpenTag = options.canBeLeftOpenTag || no
let index = 0
let last, lastTag
while (html) {
last = html
// Make sure we're not in a plaintext content element like script/style
if (!lastTag || !isPlainTextElement(lastTag)) {
let textEnd = html.indexOf('<')
if (textEnd === 0) {
// Comment:
if (comment.test(html)) {
const commentEnd = html.indexOf('-->')
if (commentEnd >= 0) {
if (options.shouldKeepComment) {
options.comment(html.substring(4, commentEnd))
}
advance(commentEnd + 3)
continue
}
}
if (conditionalComment.test(html)) {
const conditionalEnd = html.indexOf(']>')
if (conditionalEnd >= 0) {
advance(conditionalEnd + 2)
continue
}
}
// Doctype:
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
advance(doctypeMatch[0].length)
continue
}
// End tag:
const endTagMatch = html.match(endTag)
if (endTagMatch) {
const curIndex = index
advance(endTagMatch[0].length)
parseEndTag(endTagMatch[1], curIndex, index)
continue
}
// Start tag:
const startTagMatch = parseStartTag()
if (startTagMatch) {
handleStartTag(startTagMatch)
if (shouldIgnoreFirstNewline(lastTag, html)) {
advance(1)
}
continue
}
}
let text, rest, next
if (textEnd >= 0) {
rest = html.slice(textEnd)
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// < in plain text, be forgiving and treat it as text
next = rest.indexOf('<', 1)
if (next < 0) break
textEnd += next
rest = html.slice(textEnd)
}
text = html.substring(0, textEnd)
advance(textEnd)
}
if (textEnd < 0) {
text = html
html = ''
}
if (options.chars && text) {
options.chars(text)
}
} else {
let endTagLength = 0
const stackedTag = lastTag.toLowerCase()
const reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([\\s\\S]*?)(</' + stackedTag + '[^>]*>)', 'i'))
const rest = html.replace(reStackedTag, function (all, text, endTag) {
endTagLength = endTag.length
if (!isPlainTextElement(stackedTag) && stackedTag !== 'noscript') {
text = text
.replace(/<!--([\s\S]*?)-->/g, '$1')
.replace(/<!\[CDATA\[([\s\S]*?)]]>/g, '$1')
}
if (shouldIgnoreFirstNewline(stackedTag, text)) {
text = text.slice(1)
}
if (options.chars) {
options.chars(text)
}
return ''
})
index += html.length - rest.length
html = rest
parseEndTag(stackedTag, index - endTagLength, index)
}
if (html === last) {
options.chars && options.chars(html)
if (process.env.NODE_ENV !== 'production' && !stack.length && options.warn) {
options.warn(`Mal-formatted tag at end of template: "${html}"`)
}
break
}
}
// Clean up any remaining tags
parseEndTag()
parseHTML中涉及几个方法,一一来看看:
-
advace
function advance (n) { index += n html = html.substring(n) }这里可以把index理解成指向待解析htmlString索引的指针,该函数将index指针向后移n位,然后从n截取一段新的htmlString。只要一部分内容解析完毕,指针就会往后移。
-
parseStartTag
function parseStartTag () { // const startTagOpen = /^<((?:[a-zA-Z_][\w\-\.]*\:)?[a-zA-Z_][\w\-\.]*)/ const start = html.match(startTagOpen) // 正则匹配开始标签 if (start) { const match = { tagName: start[1], attrs: [], start: index } advance(start[0].length) let end, attr // const startTagClose = /^\s*(\/?)>/ while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) { advance(attr[0].length) match.attrs.push(attr) } if (end) { match.unarySlash = end[1] advance(end[0].length) match.end = index return match } } }parseStartTag主要负责解析开始标签,例如’<div>’, ‘<my-component id=”component” @click=handleClick>’。通过正则匹配获取标签名,属性列表等信息,将它们包装成一个match对象返回。如果我们的’template’选项是’<div class=”app” @click=”handleClick”></div>‘,就会被解析成:
{ tagName: div, attrs: [ [ " class="app"", "class", "=", "app", undefined, undefined ], [ " @click="handleClick"", "@click", "=", "handleClick", undefined, undefined ] ], unarySlash: '' start: 0, end: 37 } -
handleStartTag
function handleStartTag (match) { const tagName = match.tagName // div const unarySlash = match.unarySlash // '' if (expectHTML) { // true if (lastTag === 'p' && isNonPhrasingTag(tagName)) { parseEndTag(lastTag) } if (canBeLeftOpenTag(tagName) && lastTag === tagName) { parseEndTag(tagName) } } const unary = isUnaryTag(tagName) || !!unarySlash const l = match.attrs.length const attrs = new Array(l) for (let i = 0; i < l; i++) { const args = match.attrs[i] const value = args[3] || args[4] || args[5] || '' // handleClick attrs[i] = { name: args[1], // @click value: decodeAttr( // handleClick value, options.shouldDecodeNewlines ) } } if (!unary) { stack.push({ tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs: attrs }) lastTag = tagName } if (options.start) { options.start(tagName, attrs, unary, match.start, match.end) } }handleStartTag主要负责处理解析开始标签之后得到的match对象。首先,如果是自闭合标签则直接解析结束标签;其次,生成新的由name和value键值对组成的属性列表attrs;然后把tagName、小写的tagName和attrs添加到stack列表中,并将当前标签标记为lastTag;最后,执行start选项。
-
parseEndTag
function parseEndTag (tagName, start, end) { let pos, lowerCasedTagName if (start == null) start = index // 38 if (end == null) end = index // 38 if (tagName) { lowerCasedTagName = tagName.toLowerCase() // div } // Find the closest opened tag of the same type if (tagName) { for (pos = stack.length - 1; pos >= 0; pos--) { if (stack[pos].lowerCasedTag === lowerCasedTagName) { break } } } else { // If no tag name is provided, clean shop pos = 0 } if (pos >= 0) { // Close all the open elements, up the stack for (let i = stack.length - 1; i >= pos; i--) { if (process.env.NODE_ENV !== 'production' && (i > pos || !tagName) && options.warn ) { options.warn( `tag <${stack[i].tag}> has no matching end tag.` ) } if (options.end) { options.end(stack[i].tag, start, end) } } // Remove the open elements from the stack stack.length = pos lastTag = pos && stack[pos - 1].tag } else if (lowerCasedTagName === 'br') { if (options.start) { options.start(tagName, [], true, start, end) } } else if (lowerCasedTagName === 'p') { if (options.start) { options.start(tagName, [], false, start, end) } if (options.end) { options.end(tagName, start, end) } } }首先,遍历stack列表,找到与当前标签名匹配的标签在stack中的位置pos,如果没有找到,则pos=0。其次,如果匹配到开始标签,遍历当前标签及其以后的所有标签,对它们执行end操作,并从stack中将它们删除,然后把此时stack列表的最后一个标签标记为lastTag;如果是br标签,则执行start操作;如果是p标签,则先执行start操作,后执行end操作。
-
parseHTML
分析完这几个方法之后,我们再回过头来看看parseHTML做了什么。
export function parseHTML (html, options) { const stack = [] const expectHTML = options.expectHTML const isUnaryTag = options.isUnaryTag || no const canBeLeftOpenTag = options.canBeLeftOpenTag || no let index = 0 let last, lastTag while (html) { // 循环处理传入的html last = html // Make sure we're not in a plaintext content element like script/style if (!lastTag || !isPlainTextElement(lastTag)) { // 如果lastTag不是script/style/textarea标签 let textEnd = html.indexOf('<') // html是否包含'<' if (textEnd === 0) { // 如果是以'<'开头 // Comment: if (comment.test(html)) { // 进一步判断是不是注释的开头 const commentEnd = html.indexOf('-->') // 获取注释结束索引 if (commentEnd >= 0) { if (options.shouldKeepComment) { options.comment(html.substring(4, commentEnd)) } advance(commentEnd + 3) // index往后移,并截取剩下的部分html continue // 进入下一次循环 } } if (conditionalComment.test(html)) { // 进一步判断是不是条件注释的开头 const conditionalEnd = html.indexOf(']>') // 获取注释结束索引 if (conditionalEnd >= 0) { advance(conditionalEnd + 2) // index往后移,并截取剩下的部分html continue // 进入下一次循环 } } // Doctype: const doctypeMatch = html.match(doctype) // 正则匹配/^<!DOCTYPE [^>]+>/i if (doctypeMatch) { advance(doctypeMatch[0].length) // 跳过Doctype continue // 继续解析剩下的html } // End tag: const endTagMatch = html.match(endTag) // 正则匹配结束标签 if (endTagMatch) { const curIndex = index advance(endTagMatch[0].length) // index往后移,并截取剩下的部分html parseEndTag(endTagMatch[1], curIndex, index) // 执行parseEndTag continue // 继续解析剩下的html } // Start tag: const startTagMatch = parseStartTag() // 按顺序解析开始标签的开始、属性、结束部分 if (startTagMatch) { handleStartTag(startTagMatch) // 处理attrs并将标签加入stack堆栈 if (shouldIgnoreFirstNewline(lastTag, html)) { advance(1) } continue } } let text, rest, next if (textEnd >= 0) { // 如果不是以'<'开头 rest = html.slice(textEnd) // 截取textEnd之后的html while ( !endTag.test(rest) && !startTagOpen.test(rest) && !comment.test(rest) && !conditionalComment.test(rest) ) { // 循环检查是否有标签或注释特征,如果textEnd之后的html还有第二个'<',则把第二个之前的所有字符包含'<'都当成纯文本 // < in plain text, be forgiving and treat it as text next = rest.indexOf('<', 1) if (next < 0) break // 如果找不到第二个'<',则结束循环 textEnd += next rest = html.slice(textEnd) } text = html.substring(0, textEnd) // 得到纯文本 advance(textEnd) // 从文本结束索引处截取html } if (textEnd < 0) { // 如果html不包含'<',则html都被当成纯文本处理 text = html html = '' } if (options.chars && text) { // 执行chars选项 options.chars(text) } } else { // script/style/textarea标签的处理 let endTagLength = 0 const stackedTag = lastTag.toLowerCase() const reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([\\s\\S]*?)(</' + stackedTag + '[^>]*>)', 'i')) const rest = html.replace(reStackedTag, function (all, text, endTag) { endTagLength = endTag.length if (!isPlainTextElement(stackedTag) && stackedTag !== 'noscript') { text = text .replace(/<!--([\s\S]*?)-->/g, '$1') .replace(/<!\[CDATA\[([\s\S]*?)]]>/g, '$1') } if (shouldIgnoreFirstNewline(stackedTag, text)) { text = text.slice(1) } if (options.chars) { options.chars(text) } return '' }) index += html.length - rest.length html = rest parseEndTag(stackedTag, index - endTagLength, index) } if (html === last) { options.chars && options.chars(html) if (process.env.NODE_ENV !== 'production' && !stack.length && options.warn) { options.warn(`Mal-formatted tag at end of template: "${html}"`) } break } } // Clean up any remaining tags parseEndTag()这里先忽略script、style、textarea标签的处理。parseHTML主要是通过while循环和正则匹配来解析html,其中还用’<’的位置来判断将html解析成什么内容:
- 等于 0:注释、条件注释、doctype、开始标签或结束标签
- 大于等于 0:包含’<’字符的文本、表达式
- 小于 0:文本、表达式
这样,解析完一段就截取html剩下的片段,继续while循环,直到html变为’‘。
parseHTML还在某些地方执行了start选项、end选项、chars等选项,这是在调用parseHTML方法时传入的选项的方法,我们来看看这几个方法:
-
start
start (tag, attrs, unary) { // check namespace. // inherit parent ns if there is one const ns = (currentParent && currentParent.ns) || platformGetTagNamespace(tag) let element: ASTElement = createASTElement(tag, attrs, currentParent) // 生成ASTElement对象 if (ns) { element.ns = ns } if (isForbiddenTag(element) && !isServerRendering()) { // 如果el是style或script标签 element.forbidden = true process.env.NODE_ENV !== 'production' && warn( 'Templates should only be responsible for mapping the state to the ' + 'UI. Avoid placing tags with side-effects in your templates, such as ' + `<${tag}>` + ', as they will not be parsed.' ) } // apply pre-transforms // 执行preTransformNode方法 for (let i = 0; i < preTransforms.length; i++) { element = preTransforms[i](element, options) || element } if (!inVPre) { processPre(element) // 获取并从el中删除'v-pre'属性,如果找到'v-pre'属性,则el.pre=true if (element.pre) { inVPre = true } } if (platformIsPreTag(element.tag)) { // 检查el是否是pre标签 inPre = true } if (inVPre) { // 如果有'v-pre'属性属性 processRawAttrs(element) // 给el绑定attrs属性,attrs通过el.attrsList变换而来 } else if (!element.processed) { // structural directives 处理指令 processFor(element) // 绑定el.for, el.alais, el.iterator1, el.iterator2 processIf(element) // 绑定el.if, el.else, el.elseif, el.ifConditions processOnce(element) // 绑定el.once // element-scope stuff processElement(element, options) // 处理key,ref,slot,component,执行transformNode(element, options)处理style和class属性,处理其他attrs } function checkRootConstraints (el) { if (process.env.NODE_ENV !== 'production') { if (el.tag === 'slot' || el.tag === 'template') { warnOnce( `Cannot use <${el.tag}> as component root element because it may ` + 'contain multiple nodes.' ) } if (el.attrsMap.hasOwnProperty('v-for')) { warnOnce( 'Cannot use v-for on stateful component root element because ' + 'it renders multiple elements.' ) } } } // tree management if (!root) { root = element checkRootConstraints(root) // 检查根元素是不是slot或template,如果是警告;检查根元素是否有'v-for'指令,有则给出警告 } else if (!stack.length) { // allow root elements with v-if, v-else-if and v-else if (root.if && (element.elseif || element.else)) { checkRootConstraints(element) addIfCondition(root, { exp: element.elseif, block: element }) } else if (process.env.NODE_ENV !== 'production') { warnOnce( `Component template should contain exactly one root element. ` + `If you are using v-if on multiple elements, ` + `use v-else-if to chain them instead.` ) } } if (currentParent && !element.forbidden) { if (element.elseif || element.else) { processIfConditions(element, currentParent) } else if (element.slotScope) { // scoped slot currentParent.plain = false const name = element.slotTarget || '"default"' ;(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element } else { currentParent.children.push(element) element.parent = currentParent } } if (!unary) { currentParent = element stack.push(element) // 为什么又要往stack添加一次? } else { endPre(element) // inVPre=false or inPre=false } // apply post-transforms for (let i = 0; i < postTransforms.length; i++) { postTransforms[i](element, options) // 没找到该函数? } }start主要是为当前解析的标签生成ASTElement对象(简称:el);接着使用preTransformNode方法对el进行预处理;再接着对标签上的指令和属性进行处理,然后进行树结构的构建,确定el的root, parent, children等属性。总结下来就是生成树节点,构建树结构(关联树节点)。
-
end
end () { // remove trailing whitespace const element = stack[stack.length - 1] const lastNode = element.children[element.children.length - 1] if (lastNode && lastNode.type === 3 && lastNode.text === ' ' && !inPre) { element.children.pop() } // pop stack stack.length -= 1 currentParent = stack[stack.length - 1] endPre(element) }end主要做的是删除el的值为空格的最后子节点,以及删除stack堆栈的最后一个并让currentParent等于当前stack堆栈的最后一个,currentParent表示当前的父级元素。
-
chars
chars (text: string) { const children = currentParent.children text = inPre || text.trim() ? isTextTag(currentParent) ? text : decodeHTMLCached(text) // only preserve whitespace if its not right after a starting tag : preserveWhitespace && children.length ? ' ' : '' if (text) { let expression if (!inVPre && text !== ' ' && (expression = parseText(text, delimiters))) { children.push({ type: 2, expression, text }) } else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') { children.push({ type: 3, text }) } } }chars方法用来处理非html标签的文本。如果是表达式,通过parseText方法解析文本内容并传递给当前元素的children;如果是普通文本直接传递给当前元素的children。
parse执行完毕之后返回了root,这就是生成的AST。我们拿Vue的一个示例来看:
<!DOCTYPE html>
<html>
<head>
<title>Vue.js github commits example</title>
<style>
#demo {
font-family: 'Helvetica', Arial, sans-serif;
}
a {
text-decoration: none;
color: #f66;
}
li {
line-height: 1.5em;
margin-bottom: 20px;
}
.author, .date {
font-weight: bold;
}
</style>
<!-- Delete ".min" for console warnings in development -->
<script src="../../dist/vue.js"></script>
</head>
<body>
<div id="demo">
<h1>Latest Vue.js Commits</h1>
<template v-for="branch in branches">
<input type="radio"
:id="branch"
:value="branch"
name="branch"
v-model="currentBranch">
<label :for="branch"></label>
</template>
<p>vuejs/vue@</p>
<ul>
<li v-for="record in commits">
<a :href="record.html_url" target="_blank" class="commit"></a>
- <span class="message"></span><br>
by <span class="author"><a :href="record.author.html_url" target="_blank"></a></span>
at <span class="date"></span>
</li>
</ul>
</div>
<script>
new Vue({
el: '#demo',
data: {
branches: ['master', 'dev'],
currentBranch: 'master',
commits: null
},
created: function () {
// this.fetchData()
},
watch: {
currentBranch: 'fetchData'
},
filters: {
truncate: function (v) {
var newline = v.indexOf('\n')
return newline > 0 ? v.slice(0, newline) : v
},
formatDate: function (v) {
return v.replace(/T|Z/g, ' ')
}
},
methods: {
fetchData: function () {
var xhr = new XMLHttpRequest()
var self = this
xhr.open('GET', apiURL + self.currentBranch)
xhr.onload = function () {
self.commits = JSON.parse(xhr.responseText)
console.log(self.commits[0].html_url)
}
xhr.send()
}
}
})
</script>
</body>
</html>
最后生成的AST如下

1.1.1. optimize
export function optimize (root: ?ASTElement, options: CompilerOptions) {
if (!root) return
isStaticKey = genStaticKeysCached(options.staticKeys || '')
isPlatformReservedTag = options.isReservedTag || no
// first pass: mark all non-static nodes.
markStatic(root)
// second pass: mark static roots.
markStaticRoots(root, false)
}
optimize递归地给AST所有节点绑定static属性,给所有具有子节点的节点上绑定staticRoot属性,这样我们就可以在刷新节点或patching时忽略这些静态节点。具体是怎么判定当前节点是静态节点或静态根节点这里就不详述了,如果您感兴趣可以去看源码。
1.1.2. generate
export function generate (
ast: ASTElement | void,
options: CompilerOptions
): CodegenResult {
const state = new CodegenState(options)
const code = ast ? genElement(ast, state) : '_c("div")'
return {
render: `with(this){return ${code}}`,
staticRenderFns: state.staticRenderFns
}
}
generate首先创建了一个CodegenState对象,其次执行genElement(ast, state),最后返回render字符串函数以及state.staticRenderFns。先来看看CodegenState构造函数:
export class CodegenState {
options: CompilerOptions;
warn: Function;
transforms: Array<TransformFunction>;
dataGenFns: Array<DataGenFunction>;
directives: { [key: string]: DirectiveFunction };
maybeComponent: (el: ASTElement) => boolean;
onceId: number;
staticRenderFns: Array<string>;
constructor (options: CompilerOptions) {
this.options = options
this.warn = options.warn || baseWarn
this.transforms = pluckModuleFunction(options.modules, 'transformCode')
this.dataGenFns = pluckModuleFunction(options.modules, 'genData')
this.directives = extend(extend({}, baseDirectives), options.directives)
const isReservedTag = options.isReservedTag || no
this.maybeComponent = (el: ASTElement) => !isReservedTag(el.tag)
this.onceId = 0
this.staticRenderFns = []
}
}
CodegenState主要是通过传入的options进行初始化,transforms和dataGenFns是方法列表,这里它们分别是:
this.transforms = []
this.dataGenFns = [style[genData], class[genData]
再来看看genElement函数:
export function genElement (el: ASTElement, state: CodegenState): string {
if (el.staticRoot && !el.staticProcessed) {
return genStatic(el, state)
} else if (el.once && !el.onceProcessed) {
return genOnce(el, state)
} else if (el.for && !el.forProcessed) {
return genFor(el, state)
} else if (el.if && !el.ifProcessed) {
return genIf(el, state)
} else if (el.tag === 'template' && !el.slotTarget) {
return genChildren(el, state) || 'void 0'
} else if (el.tag === 'slot') {
return genSlot(el, state)
} else {
// component or element
let code
if (el.component) {
code = genComponent(el.component, el, state)
} else {
const data = el.plain ? undefined : genData(el, state)
const children = el.inlineTemplate ? null : genChildren(el, state, true)
code = `_c('${el.tag}'${
data ? `,${data}` : '' // data
}${
children ? `,${children}` : '' // children
})`
}
// module transforms
for (let i = 0; i < state.transforms.length; i++) {
code = state.transforms[i](el, code)
}
return code
}
}
genElement递归地根据el的拥有属性选择不同的生成函数,一旦用某一种生成函数处理过,就把*Processed标记为true。上面的案列执行完genElement会得到:
"_c('div',{attrs:{"id":"demo"}},[_c('h1',[_v("Latest Vue.js Commits")]),_v(" "),_l((branches),function(branch){return [_c('input',{directives:[{name:"model",rawName:"v-model",value:(currentBranch),expression:"currentBranch"}],attrs:{"type":"radio","id":branch,"name":"branch"},domProps:{"value":branch,"checked":_q(currentBranch,branch)},on:{"change":function($event){currentBranch=branch}}}),_v(" "),_c('label',{attrs:{"for":branch}},[_v(_s(branch))])]}),_v(" "),_c('p',[_v("vuejs/vue@"+_s(currentBranch))]),_v(" "),_c('ul',_l((commits),function(record){return _c('li',[_c('a',{staticClass:"commit",attrs:{"href":record.html_url,"target":"_blank"}},[_v(_s(record.sha.slice(0, 7)))]),_v("\n - "),_c('span',{staticClass:"message"},[_v(_s(_f("truncate")(record.commit.message)))]),_c('br'),_v("\n by "),_c('span',{staticClass:"author"},[_c('a',{attrs:{"href":record.author.html_url,"target":"_blank"}},[_v(_s(record.commit.author.name))])]),_v("\n at "),_c('span',{staticClass:"date"},[_v(_s(_f("formatDate")(record.commit.author.date)))])])}))],2)"
最终得到的code是:
{
render: "with(this){return _c('div',{attrs:{"id":"demo"}},[_c('h1',[_v("Latest Vue.js Commits")]),_v(" "),_l((branches),function(bra...",
staticRenderFns: []
}
最后render函数字符串会通过new Function()转换成render函数。
2. 思考
2.0 Why ‘with’?
render函数为什么要用with进行包装呢?在学习javascript的时候,书籍和规范总是警告我们要慎用和少用with,因为它会带来语义不明,作用域混乱的弊端。尤大大在知乎对该问题进行了解答:

利:
with语句可以在不造成性能损失的情況下,减少变量的长度。其造成的附加计算量很少。使用’with’可以减少不必要的指针路径解析运算。需要注意的是,很多情況下,也可以不使用with语句,而是使用一个临时变量来保存指针,来达到同样的效果。弊:
with语句使得程序在查找变量值时,都是先在指定的对象中查找。所以那些本来不是这个对象的属性的变量,查找起来将会很慢。如果是在对性能要求较高的场合,’with’下面的statement语句中的变量,只应该包含这个指定对象的属性。
2.1 render()
render函数是在什么地方被调用的呢?在本站Vue Constractor一文中提到过,构造函数设计过程中执行了renderMixin(Vue),renderMixin在Vue.prototype上绑定了_render方法,_rende方法中调用了vnode = render.call(vm._renderProxy, vm.$createElement),而_render方法又是在public mount中被调用的,来看看源码:
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
vm.$el = el
// 如果 render 不存在,则赋值为返回值为 VNode 实例的 createEmptyVNode 函数
if (!vm.$options.render) {
vm.$options.render = createEmptyVNode
}
// 执行 beforeMount 生命周期函数
callHook(vm, 'beforeMount')
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
updateComponent = () => {
const name = vm._name
const id = vm._uid
const startTag = `vue-perf-start:${id}`
const endTag = `vue-perf-end:${id}`
mark(startTag)
const vnode = vm._render() // 执行render函数
mark(endTag)
measure(`vue ${name} render`, startTag, endTag)
mark(startTag)
vm._update(vnode, hydrating)
mark(endTag)
measure(`vue ${name} patch`, startTag, endTag)
}
} else {
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
}
// 实例化一个 Watcher 对象,请移步下面的 Watcher 构造函数,这个 Watcher 的 getter 没有返回值
vm._watcher = new Watcher(vm, updateComponent, noop)
hydrating = false
// manually mounted instance, call mounted on self
// mounted is called for render-created child components in its inserted hook
// 如果 $vnode 属性为空,则执行 mounted 生命周期函数
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
return vm
}
export const createEmptyVNode = (text: string = '') => {
const node = new VNode()
node.text = text
node.isComment = true
return node
}
export function callHook (vm: Component, hook: string) {
const handlers = vm.$options[hook]
if (handlers) {
for (let i = 0, j = handlers.length; i < j; i++) {
try {
handlers[i].call(vm)
} catch (e) {
handleError(e, vm, `${hook} hook`)
}
}
}
if (vm._hasHookEvent) {
vm.$emit('hook:' + hook)
}
}
由此可见,render函数是在beforeMount之后,mounted之前被调用的,这就是为什么在mounted之前的生命周期函数里,我们不能操作dom的原因。
2.2 Vue单文件编译
本文只说到如何编译template选项,但是在实际开发过程中,开发者们常常会用Vue单文件,那么Vue单文件是怎么被编译的呢,我想应该是由vue-loader来完成的。纯属个人臆想,有待验证 : )。
3. 总结
- Vue的模版编译是在挂载的时候执行的
- Vue的编译过程分为三个阶段:parse、optimize、generate
- parse将template由htmlString解析成AST
- optimize标记AST中的静态节点和静态根节点
- generate根据AST生成render函数字符串
其中涉及到的方法本文只是做了简单的解析,有些地方笔者尚未理解透彻,如有不当指出请指出。